【并查集】并查集详解
算法熟记-并查集
1. 简述
并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。常常在使用中以森林来表示。
需要实现的操作有:合并两个集合,判断两个元素是否属于一个集合。
这里介绍的主要是普通的并查集,很多情况下使用的并查集是需要扩展的,根据使用情况的不同,有很多差别,这里仅仅是最基本的算法。
2. 复杂度
T=O(n*α(n)) , 其中α(x),对于x=宇宙中原子数之和,α(x)不大于4。事实上,路经压缩后的并查集的复杂度是一个很小的常数。
3. 伪代码
没有使用路径压缩和启发式的方法。
 // 初始化并查集#define N 100int father[N];void init() { for(int i=0; i<N; i++) father[i] = i;}// 合并两个元素所在的集合
// 初始化并查集#define N 100int father[N];void init() { for(int i=0; i<N; i++) father[i] = i;}// 合并两个元素所在的集合void union(int x,int y) {
x = getfather(x);
y = getfather(y);
if(x!= y)
father[x]=y;
}
// 判断两个元素是否属于同一个集合
bool same(int x,int y) {
return getfather(x)==getfather(y);
}
// 获取根结点
int getfather(int x) {
while(x != father[x])
x = father[x];
return x;
}
使用路径压缩,改进getfather。
// 获取根结点int getfather(int x) {
if(x != father[x])
father[x] = getfather(father[x]); // 路径压缩修改的是father数组 return father[x];
}
转自点击打开链接
这个文章是几年前水acm的时候转的, 当时也不知道作者是谁, 要是有人知道的话说一下吧
并查集是我暑假从高手那里学到的一招,觉得真是太精妙的设计了。以前我无法解决的一类问题竟然可以用如此简单高效的方法搞定。不分享出来真是对不起party了。(party:我靠,关我嘛事啊?我跟你很熟么?)
来看一个实例,杭电1232畅通工程
首先在地图上给你若干个城镇,这些城镇都可以看作点,然后告诉你哪些对城镇之间是有道路直接相连的。最后要解决的是整幅图的连通性问题。比如随意给你两个点,让你判断它们是否连通,或者问你整幅图一共有几个连通分支,也就是被分成了几个互相独立的块。像畅通工程这题,问还需要修几条路,实质就是求有几个连通分支。如果是1个连通分支,说明整幅图上的点都连起来了,不用再修路了;如果是2个连通分支,则只要再修1条路,从两个分支中各选一个点,把它们连起来,那么所有的点都是连起来的了;如果是3个连通分支,则只要再修两条路……
以下面这组数据输入数据来说明
4 2 1 3 4 3
第一行告诉你,一共有4个点,2条路。下面两行告诉你,1、3之间有条路,4、3之间有条路。那么整幅图就被分成了1-3-4和2两部分。只要再加一条路,把2和其他任意一个点连起来,畅通工程就实现了,那么这个这组数据的输出结果就是1。好了,现在编程实现这个功能吧,城镇有几百个,路有不知道多少条,而且可能有回路。 这可如何是好?
我以前也不会呀,自从用了并查集之后,嗨,效果还真好!我们全家都用它!
并查集由一个整数型的数组和两个函数构成。数组pre[]记录了每个点的前导点是什么,函数find是查找,join是合并。
为了解释并查集的原理,我将举一个更有爱的例子。 话说江湖上散落着各式各样的大侠,有上千个之多。他们没有什么正当职业,整天背着剑在外面走来走去,碰到和自己不是一路人的,就免不了要打一架。但大侠们有一个优点就是讲义气,绝对不打自己的朋友。而且他们信奉“朋友的朋友就是我的朋友”,只要是能通过朋友关系串联起来的,不管拐了多少个弯,都认为是自己人。这样一来,江湖上就形成了一个一个的群落,通过两两之间的朋友关系串联起来。而不在同一个群落的人,无论如何都无法通过朋友关系连起来,于是就可以放心往死了打。但是两个原本互不相识的人,如何判断是否属于一个朋友圈呢?
我们可以在每个朋友圈内推举出一个比较有名望的人,作为该圈子的代表人物,这样,每个圈子就可以这样命名“齐达内朋友之队”“罗纳尔多朋友之队”……两人只要互相对一下自己的队长是不是同一个人,就可以确定敌友关系了。
但是还有问题啊,大侠们只知道自己直接的朋友是谁,很多人压根就不认识队长,要判断自己的队长是谁,只能漫无目的的通过朋友的朋友关系问下去:“你是不是队长?你是不是队长?”这样一来,队长面子上挂不住了,而且效率太低,还有可能陷入无限循环中。于是队长下令,重新组队。队内所有人实行分等级制度,形成树状结构,我队长就是根节点,下面分别是二级队员、三级队员。每个人只要记住自己的上级是谁就行了。遇到判断敌友的时候,只要一层层向上问,直到最高层,就可以在短时间内确定队长是谁了。由于我们关心的只是两个人之间是否连通,至于他们是如何连通的,以及每个圈子内部的结构是怎样的,甚至队长是谁,并不重要。所以我们可以放任队长随意重新组队,只要不搞错敌友关系就好了。于是,门派产生了。
http://i3.6.cn/cvbnm/6f/ec/f4/1e9cfcd3def64d26ed1a49d72c1f6db9.jpg
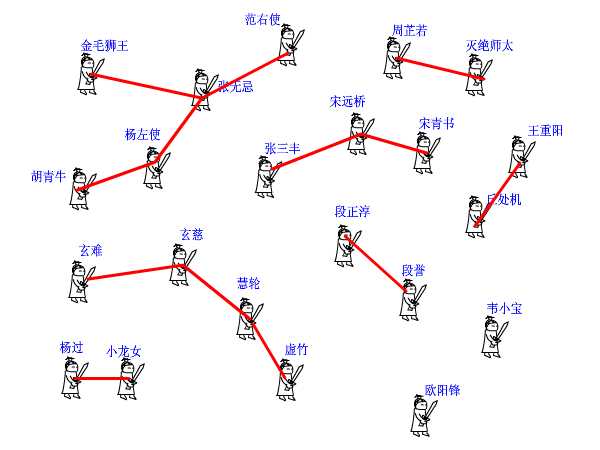
下面我们来看并查集的实现。 int pre[1000]; 这个数组,记录了每个大侠的上级是谁。大侠们从1或者0开始编号(依据题意而定),pre[15]=3就表示15号大侠的上级是3号大侠。如果一个人的上级就是他自己,那说明他就是掌门人了,查找到此为止。也有孤家寡人自成一派的,比如欧阳锋,那么他的上级就是他自己。每个人都只认自己的上级。比如胡青牛同学只知道自己的上级是杨左使。张无忌是谁?不认识!要想知道自己的掌门是谁,只能一级级查上去。 find这个函数就是找掌门用的,意义再清楚不过了(路径压缩算法先不论,后面再说)。
再来看看join函数,就是在两个点之间连一条线,这样一来,原先它们所在的两个板块的所有点就都可以互通了。这在图上很好办,画条线就行了。但我们现在是用并查集来描述武林中的状况的,一共只有一个pre[]数组,该如何实现呢? 还是举江湖的例子,假设现在武林中的形势如图所示。虚竹小和尚与周芷若MM是我非常喜欢的两个人物,他们的终极boss分别是玄慈方丈和灭绝师太,那明显就是两个阵营了。我不希望他们互相打架,就对他俩说:“你们两位拉拉勾,做好朋友吧。”他们看在我的面子上,同意了。这一同意可非同小可,整个少林和峨眉派的人就不能打架了。这么重大的变化,可如何实现呀,要改动多少地方?其实非常简单,我对玄慈方丈说:“大师,麻烦你把你的上级改为灭绝师太吧。这样一来,两派原先的所有人员的终极boss都是师太,那还打个球啊!反正我们关心的只是连通性,门派内部的结构不要紧的。”玄慈一听肯定火大了:“我靠,凭什么是我变成她手下呀,怎么不反过来?我抗议!”抗议无效,上天安排的,最大。反正谁加入谁效果是一样的,我就随手指定了一个。这段函数的意思很明白了吧?
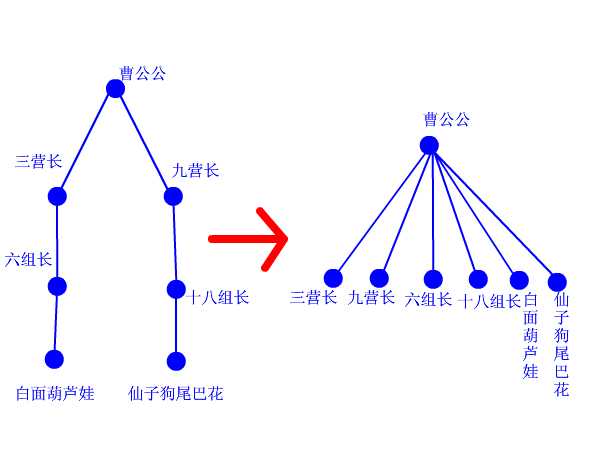
再来看看路径压缩算法。建立门派的过程是用join函数两个人两个人地连接起来的,谁当谁的手下完全随机。最后的树状结构会变成什么胎唇样,我也完全无法预计,一字长蛇阵也有可能。这样查找的效率就会比较低下。最理想的情况就是所有人的直接上级都是掌门,一共就两级结构,只要找一次就找到掌门了。哪怕不能完全做到,也最好尽量接近。这样就产生了路径压缩算法。 设想这样一个场景:两个互不相识的大侠碰面了,想知道能不能揍。 于是赶紧打电话问自己的上级:“你是不是掌门?” 上级说:“我不是呀,我的上级是谁谁谁,你问问他看看。” 一路问下去,原来两人的最终boss都是东厂曹公公。 “哎呀呀,原来是记己人,西礼西礼,在下三营六组白面葫芦娃!” “幸会幸会,在下九营十八组仙子狗尾巴花!” 两人高高兴兴地手拉手喝酒去了。 “等等等等,两位同学请留步,还有事情没完成呢!”我叫住他俩。 “哦,对了,还要做路径压缩。”两人醒悟。 白面葫芦娃打电话给他的上级六组长:“组长啊,我查过了,其习偶们的掌门是曹公公。不如偶们一起及接拜在曹公公手下吧,省得级别太低,以后查找掌门麻环。” “唔,有道理。” 白面葫芦娃接着打电话给刚才拜访过的三营长……仙子狗尾巴花也做了同样的事情。 这样,查询中所有涉及到的人物都聚集在曹公公的直接领导下。每次查询都做了优化处理,所以整个门派树的层数都会维持在比较低的水平上。路径压缩的代码,看得懂很好,看不懂也没关系,直接抄上用就行了。总之它所实现的功能就是这么个意思。
http://i3.6.cn/cvbnm/60/98/92/745b3eac68181e4ee1fa8d1b8bca38bc.jpg
以下为原文附的代码:
回到开头提出的问题,我的代码如下:
===================================================第二篇=============================================================
并查集
并查集(Union-find Sets)是一种非常精巧而实用的数据结构,它主要用于处理一些不相交集合的合并问题。一些常见的用途有求连通子图、求最小生成树的 Kruskal 算法和求最近公共祖先(Least Common Ancestors, LCA)等。
使用并查集时,首先会存在一组不相交的动态集合
每个集合可能包含一个或多个元素,并选出集合中的某个元素作为代表。每个集合中具体包含了哪些元素是不关心的,具体选择哪个元素作为代表一般也是不关心的。我们关心的是,对于给定的元素,可以很快的找到这个元素所在的集合(的代表),以及合并两个元素所在的集合,而且这些操作的时间复杂度都是常数级的。
并查集的基本操作有三个:
- makeSet(s):建立一个新的并查集,其中包含 s 个单元素集合。
- unionSet(x, y):把元素 x 和元素 y 所在的集合合并,要求 x 和 y 所在的集合不相交,如果相交则不合并。
- find(x):找到元素 x 所在的集合的代表,该操作也可以用于判断两个元素是否位于同一个集合,只要将它们各自的代表比较一下就可以了。
并查集的实现原理也比较简单,就是使用树来表示集合,树的每个节点就表示集合中的一个元素,树根对应的元素就是该集合的代表,如图 1 所示。

图 1 并查集的树表示
图中有两棵树,分别对应两个集合,其中第一个集合为
树的节点表示集合中的元素,指针表示指向父节点的指针,根节点的指针指向自己,表示其没有父节点。沿着每个节点的父节点不断向上查找,最终就可以找到该树的根节点,即该集合的代表元素。
现在,应该可以很容易的写出 makeSet 和 find 的代码了,假设使用一个足够长的数组来存储树节点(很类似之前讲到的静态链表),那么 makeSet 要做的就是构造出如图 2 的森林,其中每个元素都是一个单元素集合,即父节点是其自身:

图 2 构造并查集初始化
相应的代码如下所示,时间复杂度是
| 123456 | const int MAXSIZE = 500;int uset[MAXSIZE]; void makeSet(int size) { for(int i = 0;i < size;i++) uset[i] = i;} |
接下来,就是 find 操作了,如果每次都沿着父节点向上查找,那时间复杂度就是树的高度,完全不可能达到常数级。这里需要应用一种非常简单而有效的策略——路径压缩。
路径压缩,就是在每次查找时,令查找路径上的每个节点都直接指向根节点,如图 3 所示。

图 3 路径压缩
我准备了两个版本的 find 操作实现,分别是递归版和非递归版,不过两个版本目前并没有发现有什么明显的效率差距,所以具体使用哪个完全凭个人喜好了。
| 12345678910 | int find(int x) { if (x != uset[x]) uset[x] = find(uset[x]); return uset[x];}int find(int x) { int p = x, t; while (uset[p] != p) p = uset[p]; while (x != p) { t = uset[x]; uset[x] = p; x = t; } return x;} |
最后是合并操作 unionSet,并查集的合并也非常简单,就是将一个集合的树根指向另一个集合的树根,如图 4 所示。

图 4 并查集的合并
这里也可以应用一个简单的启发式策略——按秩合并。该方法使用秩来表示树高度的上界,在合并时,总是将具有较小秩的树根指向具有较大秩的树根。简单的说,就是总是将比较矮的树作为子树,添加到较高的树中。为了保存秩,需要额外使用一个与 uset 同长度的数组,并将所有元素都初始化为 0。
| 12345678 | void unionSet(int x, int y) { if ((x = find(x)) == (y = find(y))) return; if (rank[x] > rank[y]) uset[y] = x; else { uset[x] = y; if (rank[x] == rank[y]) rank[y]++; }} |
下面是按秩合并的并查集的完整代码,这里只包含了递归的 find 操作。
| 1234567891011121314151617181920 | const int MAXSIZE = 500;int uset[MAXSIZE];int rank[MAXSIZE]; void makeSet(int size) { for(int i = 0;i < size;i++) uset[i] = i; for(int i = 0;i < size;i++) rank[i] = 0;}int find(int x) { if (x != uset[x]) uset[x] = find(uset[x]); return uset[x];}void unionSet(int x, int y) { if ((x = find(x)) == (y = find(y))) return; if (rank[x] > rank[y]) uset[y] = x; else { uset[x] = y; if (rank[x] == rank[y]) rank[y]++; }} |
除了按秩合并,并查集还有一种常见的策略,就是按集合中包含的元素个数(或者说树中的节点数)合并,将包含节点较少的树根,指向包含节点较多的树根。这个策略与按秩合并的策略类似,同样可以提升并查集的运行速度,而且省去了额外的 rank 数组。
这样的并查集具有一个略微不同的定义,即若 uset 的值是正数,则表示该元素的父节点(的索引);若是负数,则表示该元素是所在集合的代表(即树根),而且值的相反数即为集合中的元素个数。相应的代码如下所示,同样包含递归和非递归的 find 操作:
| 12345678910111213141516171819202122232425262728293031 | const int MAXSIZE = 500;int uset[MAXSIZE]; void makeSet(int size) { for(int i = 0;i < size;i++) uset[i] = -1;}int find(int x) { if (uset[x] < 0) return x; uset[x] = find(uset[x]); return uset[x];}int find(int x) { int p = x, t; while (uset[p] >= 0) p = uset[p]; while (x != p) { t = uset[x]; uset[x] = p; x = t; } return x;}void unionSet(int x, int y) { if ((x = find(x)) == (y = find(y))) return; if (uset[x] < uset[y]) { uset[x] += uset[y]; uset[y] = x; } else { uset[y] += uset[x]; uset[x] = y; }} |
如果要获取某个元素 x 所在集合包含的元素个数,可以使用 -uset[find(x)] 得到。
并查集的空间复杂度是
作者:CYJB
出处:http://www.cnblogs.com/cyjb/
GitHub:https://github.com/CYJB/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
算法熟记-并查集
1. 简述
并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。常常在使用中以森林来表示。
需要实现的操作有:合并两个集合,判断两个元素是否属于一个集合。
这里介绍的主要是普通的并查集,很多情况下使用的并查集是需要扩展的,根据使用情况的不同,有很多差别,这里仅仅是最基本的算法。
2. 复杂度
T=O(n*α(n)) , 其中α(x),对于x=宇宙中原子数之和,α(x)不大于4。事实上,路经压缩后的并查集的复杂度是一个很小的常数。
3. 伪代码
没有使用路径压缩和启发式的方法。
// 初始化并查集#define N 100int father[N];void init() { for(int i=0; i<N; i++) father[i] = i;}// 合并两个元素所在的集合void union(int x,int y) {
x = getfather(x);
y = getfather(y);
if(x!= y)
father[x]=y;
}
// 判断两个元素是否属于同一个集合
bool same(int x,int y) {
return getfather(x)==getfather(y);
}
// 获取根结点
int getfather(int x) {
while(x != father[x])
x = father[x];
return x;
}
使用路径压缩,改进getfather。
// 获取根结点int getfather(int x) {
if(x != father[x])
father[x] = getfather(father[x]); // 路径压缩修改的是father数组 return father[x];
}
转自点击打开链接
这个文章是几年前水acm的时候转的, 当时也不知道作者是谁, 要是有人知道的话说一下吧
并查集是我暑假从高手那里学到的一招,觉得真是太精妙的设计了。以前我无法解决的一类问题竟然可以用如此简单高效的方法搞定。不分享出来真是对不起party了。(party:我靠,关我嘛事啊?我跟你很熟么?)
来看一个实例,杭电1232畅通工程
首先在地图上给你若干个城镇,这些城镇都可以看作点,然后告诉你哪些对城镇之间是有道路直接相连的。最后要解决的是整幅图的连通性问题。比如随意给你两个点,让你判断它们是否连通,或者问你整幅图一共有几个连通分支,也就是被分成了几个互相独立的块。像畅通工程这题,问还需要修几条路,实质就是求有几个连通分支。如果是1个连通分支,说明整幅图上的点都连起来了,不用再修路了;如果是2个连通分支,则只要再修1条路,从两个分支中各选一个点,把它们连起来,那么所有的点都是连起来的了;如果是3个连通分支,则只要再修两条路……
以下面这组数据输入数据来说明
4 2 1 3 4 3
第一行告诉你,一共有4个点,2条路。下面两行告诉你,1、3之间有条路,4、3之间有条路。那么整幅图就被分成了1-3-4和2两部分。只要再加一条路,把2和其他任意一个点连起来,畅通工程就实现了,那么这个这组数据的输出结果就是1。好了,现在编程实现这个功能吧,城镇有几百个,路有不知道多少条,而且可能有回路。 这可如何是好?
我以前也不会呀,自从用了并查集之后,嗨,效果还真好!我们全家都用它!
并查集由一个整数型的数组和两个函数构成。数组pre[]记录了每个点的前导点是什么,函数find是查找,join是合并。
为了解释并查集的原理,我将举一个更有爱的例子。 话说江湖上散落着各式各样的大侠,有上千个之多。他们没有什么正当职业,整天背着剑在外面走来走去,碰到和自己不是一路人的,就免不了要打一架。但大侠们有一个优点就是讲义气,绝对不打自己的朋友。而且他们信奉“朋友的朋友就是我的朋友”,只要是能通过朋友关系串联起来的,不管拐了多少个弯,都认为是自己人。这样一来,江湖上就形成了一个一个的群落,通过两两之间的朋友关系串联起来。而不在同一个群落的人,无论如何都无法通过朋友关系连起来,于是就可以放心往死了打。但是两个原本互不相识的人,如何判断是否属于一个朋友圈呢?
我们可以在每个朋友圈内推举出一个比较有名望的人,作为该圈子的代表人物,这样,每个圈子就可以这样命名“齐达内朋友之队”“罗纳尔多朋友之队”……两人只要互相对一下自己的队长是不是同一个人,就可以确定敌友关系了。
但是还有问题啊,大侠们只知道自己直接的朋友是谁,很多人压根就不认识队长,要判断自己的队长是谁,只能漫无目的的通过朋友的朋友关系问下去:“你是不是队长?你是不是队长?”这样一来,队长面子上挂不住了,而且效率太低,还有可能陷入无限循环中。于是队长下令,重新组队。队内所有人实行分等级制度,形成树状结构,我队长就是根节点,下面分别是二级队员、三级队员。每个人只要记住自己的上级是谁就行了。遇到判断敌友的时候,只要一层层向上问,直到最高层,就可以在短时间内确定队长是谁了。由于我们关心的只是两个人之间是否连通,至于他们是如何连通的,以及每个圈子内部的结构是怎样的,甚至队长是谁,并不重要。所以我们可以放任队长随意重新组队,只要不搞错敌友关系就好了。于是,门派产生了。
http://i3.6.cn/cvbnm/6f/ec/f4/1e9cfcd3def64d26ed1a49d72c1f6db9.jpg
下面我们来看并查集的实现。 int pre[1000]; 这个数组,记录了每个大侠的上级是谁。大侠们从1或者0开始编号(依据题意而定),pre[15]=3就表示15号大侠的上级是3号大侠。如果一个人的上级就是他自己,那说明他就是掌门人了,查找到此为止。也有孤家寡人自成一派的,比如欧阳锋,那么他的上级就是他自己。每个人都只认自己的上级。比如胡青牛同学只知道自己的上级是杨左使。张无忌是谁?不认识!要想知道自己的掌门是谁,只能一级级查上去。 find这个函数就是找掌门用的,意义再清楚不过了(路径压缩算法先不论,后面再说)。
再来看看join函数,就是在两个点之间连一条线,这样一来,原先它们所在的两个板块的所有点就都可以互通了。这在图上很好办,画条线就行了。但我们现在是用并查集来描述武林中的状况的,一共只有一个pre[]数组,该如何实现呢? 还是举江湖的例子,假设现在武林中的形势如图所示。虚竹小和尚与周芷若MM是我非常喜欢的两个人物,他们的终极boss分别是玄慈方丈和灭绝师太,那明显就是两个阵营了。我不希望他们互相打架,就对他俩说:“你们两位拉拉勾,做好朋友吧。”他们看在我的面子上,同意了。这一同意可非同小可,整个少林和峨眉派的人就不能打架了。这么重大的变化,可如何实现呀,要改动多少地方?其实非常简单,我对玄慈方丈说:“大师,麻烦你把你的上级改为灭绝师太吧。这样一来,两派原先的所有人员的终极boss都是师太,那还打个球啊!反正我们关心的只是连通性,门派内部的结构不要紧的。”玄慈一听肯定火大了:“我靠,凭什么是我变成她手下呀,怎么不反过来?我抗议!”抗议无效,上天安排的,最大。反正谁加入谁效果是一样的,我就随手指定了一个。这段函数的意思很明白了吧?
再来看看路径压缩算法。建立门派的过程是用join函数两个人两个人地连接起来的,谁当谁的手下完全随机。最后的树状结构会变成什么胎唇样,我也完全无法预计,一字长蛇阵也有可能。这样查找的效率就会比较低下。最理想的情况就是所有人的直接上级都是掌门,一共就两级结构,只要找一次就找到掌门了。哪怕不能完全做到,也最好尽量接近。这样就产生了路径压缩算法。 设想这样一个场景:两个互不相识的大侠碰面了,想知道能不能揍。 于是赶紧打电话问自己的上级:“你是不是掌门?” 上级说:“我不是呀,我的上级是谁谁谁,你问问他看看。” 一路问下去,原来两人的最终boss都是东厂曹公公。 “哎呀呀,原来是记己人,西礼西礼,在下三营六组白面葫芦娃!” “幸会幸会,在下九营十八组仙子狗尾巴花!” 两人高高兴兴地手拉手喝酒去了。 “等等等等,两位同学请留步,还有事情没完成呢!”我叫住他俩。 “哦,对了,还要做路径压缩。”两人醒悟。 白面葫芦娃打电话给他的上级六组长:“组长啊,我查过了,其习偶们的掌门是曹公公。不如偶们一起及接拜在曹公公手下吧,省得级别太低,以后查找掌门麻环。” “唔,有道理。” 白面葫芦娃接着打电话给刚才拜访过的三营长……仙子狗尾巴花也做了同样的事情。 这样,查询中所有涉及到的人物都聚集在曹公公的直接领导下。每次查询都做了优化处理,所以整个门派树的层数都会维持在比较低的水平上。路径压缩的代码,看得懂很好,看不懂也没关系,直接抄上用就行了。总之它所实现的功能就是这么个意思。
http://i3.6.cn/cvbnm/60/98/92/745b3eac68181e4ee1fa8d1b8bca38bc.jpg
以下为原文附的代码:
回到开头提出的问题,我的代码如下:
===================================================第二篇=============================================================
并查集
并查集(Union-find Sets)是一种非常精巧而实用的数据结构,它主要用于处理一些不相交集合的合并问题。一些常见的用途有求连通子图、求最小生成树的 Kruskal 算法和求最近公共祖先(Least Common Ancestors, LCA)等。
使用并查集时,首先会存在一组不相交的动态集合
每个集合可能包含一个或多个元素,并选出集合中的某个元素作为代表。每个集合中具体包含了哪些元素是不关心的,具体选择哪个元素作为代表一般也是不关心的。我们关心的是,对于给定的元素,可以很快的找到这个元素所在的集合(的代表),以及合并两个元素所在的集合,而且这些操作的时间复杂度都是常数级的。
并查集的基本操作有三个:
- makeSet(s):建立一个新的并查集,其中包含 s 个单元素集合。
- unionSet(x, y):把元素 x 和元素 y 所在的集合合并,要求 x 和 y 所在的集合不相交,如果相交则不合并。
- find(x):找到元素 x 所在的集合的代表,该操作也可以用于判断两个元素是否位于同一个集合,只要将它们各自的代表比较一下就可以了。
并查集的实现原理也比较简单,就是使用树来表示集合,树的每个节点就表示集合中的一个元素,树根对应的元素就是该集合的代表,如图 1 所示。
图 1 并查集的树表示
图中有两棵树,分别对应两个集合,其中第一个集合为
树的节点表示集合中的元素,指针表示指向父节点的指针,根节点的指针指向自己,表示其没有父节点。沿着每个节点的父节点不断向上查找,最终就可以找到该树的根节点,即该集合的代表元素。
现在,应该可以很容易的写出 makeSet 和 find 的代码了,假设使用一个足够长的数组来存储树节点(很类似之前讲到的静态链表),那么 makeSet 要做的就是构造出如图 2 的森林,其中每个元素都是一个单元素集合,即父节点是其自身:
图 2 构造并查集初始化
相应的代码如下所示,时间复杂度是
| 123456 | const int MAXSIZE = 500;int uset[MAXSIZE]; void makeSet(int size) { for(int i = 0;i < size;i++) uset[i] = i;} |
接下来,就是 find 操作了,如果每次都沿着父节点向上查找,那时间复杂度就是树的高度,完全不可能达到常数级。这里需要应用一种非常简单而有效的策略——路径压缩。
路径压缩,就是在每次查找时,令查找路径上的每个节点都直接指向根节点,如图 3 所示。
图 3 路径压缩
我准备了两个版本的 find 操作实现,分别是递归版和非递归版,不过两个版本目前并没有发现有什么明显的效率差距,所以具体使用哪个完全凭个人喜好了。
| 12345678910 | int find(int x) { if (x != uset[x]) uset[x] = find(uset[x]); return uset[x];}int find(int x) { int p = x, t; while (uset[p] != p) p = uset[p]; while (x != p) { t = uset[x]; uset[x] = p; x = t; } return x;} |
最后是合并操作 unionSet,并查集的合并也非常简单,就是将一个集合的树根指向另一个集合的树根,如图 4 所示。
图 4 并查集的合并
这里也可以应用一个简单的启发式策略——按秩合并。该方法使用秩来表示树高度的上界,在合并时,总是将具有较小秩的树根指向具有较大秩的树根。简单的说,就是总是将比较矮的树作为子树,添加到较高的树中。为了保存秩,需要额外使用一个与 uset 同长度的数组,并将所有元素都初始化为 0。
| 12345678 | void unionSet(int x, int y) { if ((x = find(x)) == (y = find(y))) return; if (rank[x] > rank[y]) uset[y] = x; else { uset[x] = y; if (rank[x] == rank[y]) rank[y]++; }} |
下面是按秩合并的并查集的完整代码,这里只包含了递归的 find 操作。
| 1234567891011121314151617181920 | const int MAXSIZE = 500;int uset[MAXSIZE];int rank[MAXSIZE]; void makeSet(int size) { for(int i = 0;i < size;i++) uset[i] = i; for(int i = 0;i < size;i++) rank[i] = 0;}int find(int x) { if (x != uset[x]) uset[x] = find(uset[x]); return uset[x];}void unionSet(int x, int y) { if ((x = find(x)) == (y = find(y))) return; if (rank[x] > rank[y]) uset[y] = x; else { uset[x] = y; if (rank[x] == rank[y]) rank[y]++; }} |
除了按秩合并,并查集还有一种常见的策略,就是按集合中包含的元素个数(或者说树中的节点数)合并,将包含节点较少的树根,指向包含节点较多的树根。这个策略与按秩合并的策略类似,同样可以提升并查集的运行速度,而且省去了额外的 rank 数组。
这样的并查集具有一个略微不同的定义,即若 uset 的值是正数,则表示该元素的父节点(的索引);若是负数,则表示该元素是所在集合的代表(即树根),而且值的相反数即为集合中的元素个数。相应的代码如下所示,同样包含递归和非递归的 find 操作:
| 12345678910111213141516171819202122232425262728293031 | const int MAXSIZE = 500;int uset[MAXSIZE]; void makeSet(int size) { for(int i = 0;i < size;i++) uset[i] = -1;}int find(int x) { if (uset[x] < 0) return x; uset[x] = find(uset[x]); return uset[x];}int find(int x) { int p = x, t; while (uset[p] >= 0) p = uset[p]; while (x != p) { t = uset[x]; uset[x] = p; x = t; } return x;}void unionSet(int x, int y) { if ((x = find(x)) == (y = find(y))) return; if (uset[x] < uset[y]) { uset[x] += uset[y]; uset[y] = x; } else { uset[y] += uset[x]; uset[x] = y; }} |
如果要获取某个元素 x 所在集合包含的元素个数,可以使用 -uset[find(x)] 得到。
并查集的空间复杂度是
作者:CYJB
出处:http://www.cnblogs.com/cyjb/
GitHub:https://github.com/CYJB/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
智能推荐
注意!
本站转载的文章为个人学习借鉴使用,本站对版权不负任何法律责任。如果侵犯了您的隐私权益,请联系我们删除。