了解YARN的架构及原理
初步了解YARN的架构及原理
YARN 产生背景
MapReduce存在的问题:
1)JobTracker 单点故障。
2)JobTracker 承受的访问压力大,影响系统的扩展性。
3)不支持MapReduce之外的计算框架,比如Storm、Spark、Flink
什么是YARN
YARN 是Hadoop2.0版本新引入的资源管理系统,直接从MR1演化而来。核心思想:
将MR1中JobTracker的资源管理和作业调度两个功能分开,分别由ResourceManager和ApplicationMaster进程来实现。
1)ResourceManager:负责整个集群的资源管理和调度。
2)ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等。
YARN的出现,使得多个计算框架运行在一个集群当中。
1)每个应用程序对应一个ApplicationMaster。
2)目前可以支持多种计算框架运行在YARN上面,比如MapReduce、Storm、Spark、 Flink
YARN的基本架构
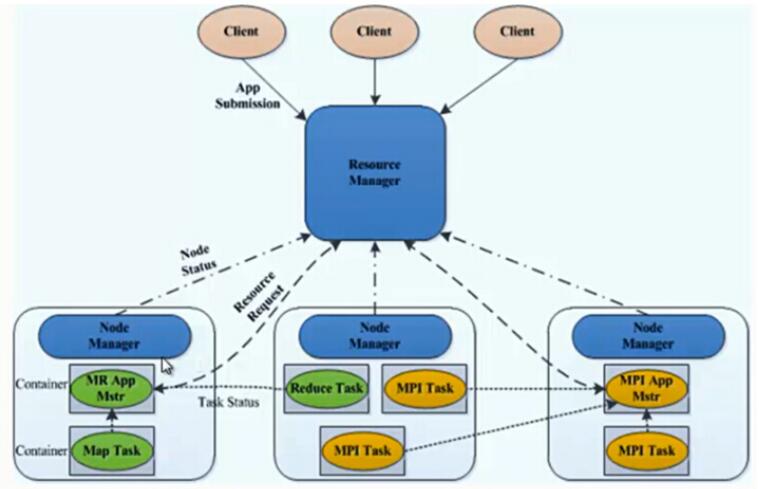
从 YARN 的架构图来看,它主要由ResourceManager、NodeManager、ApplicationMaster和Container等以下几个组件构成。
ResourceManager(RM)
RM 是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:
调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
YARN 分层结构的本质是 ResourceManager。这个实体控制整个集群并管理应用程序向基础计算资源的分配。ResourceManager 将各个资源部分(计算、内存、带宽等)精心安排
给基础 NodeManager(YARN 的每节点代理)。ResourceManager 还与 ApplicationMaster 一起分配资源,与 NodeManager 一起启动和监视它们的基础应用程序。在此上下文中,ApplicationMaster 承担了以前的 TaskTracker 的一些角色, ResourceManager 承担了 JobTracker 的角色。
(1)调度器
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。该调度器是一个“纯调度器”,它不再从事任何与具体应用程序相关的工作。
(2)应用程序管理器
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
ApplicationMaster(AM)
ApplicationMaster 管理一个在 YARN 内运行的应用程序的每个实例。ApplicationMaster负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源
使用(CPU、内存等的资源分配)。请注意,尽管目前的资源更加传统(CPU 核心、内存),但未来会带来基于手头任务的新资源类型(比如图形处理单元或专用处理设备)。从
YARN 角度讲,ApplicationMaster 是用户代码,因此存在潜在的安全问题。YARN 假设
ApplicationMaster 存在错误或者甚至是恶意的,因此将它们当作无特权的代码对待。
NodeManager(NM)
NodeManager 管理一个 YARN 集群中的每个节点。NodeManager 提供针对集群中每个
节点的服务,从监督对一个容器的终生管理到监视资源和跟踪节点健康。MRv1 通过插槽管理 Map 和 Reduce 任务的执行,而 NodeManager 管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。YARN 继续使用 HDFS 层。它的主要 NameNode 用于元数据服务,而 DataNode 用于分散在一个集群中的复制存储服务。
NM是每个节点上的资源和任务管理器,一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
Container
Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
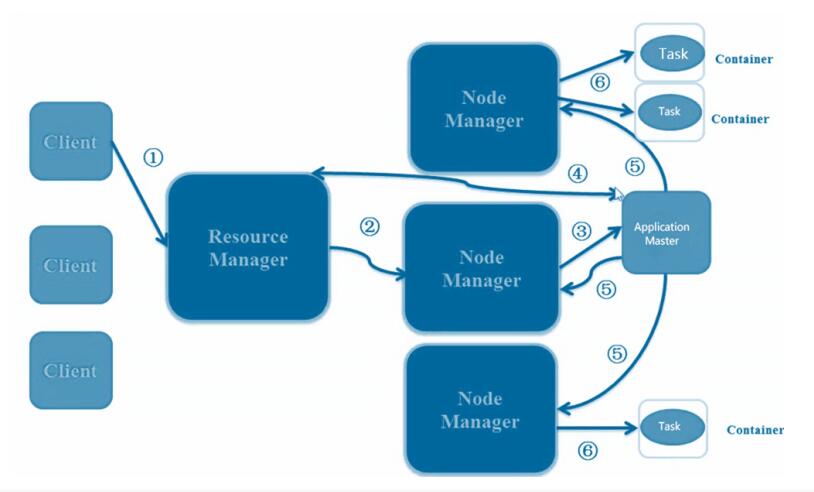
要使用一个 YARN 集群,首先需要来自包含一个应用程序的客户的请求。
ResourceManager 协商一个容器的必要资源,启动一个 ApplicationMaster 来表示已提交
的应用程序。通过使用一个资源请求协议,ApplicationMaster 协商每个节点上供应用程序使用的资源容器。执行应用程序时,ApplicationMaster 监视容器直到完成。当应用程序完
成时,ApplicationMaster 从 ResourceManager 注销其容器,执行周期就完成了。
通过上面的学习,应该明确的一点是,旧的 Hadoop 架构受到了 JobTracker 的高度约束, JobTracker 负责整个集群的资源管理和作业调度。新的 YARN 架构打破了这种模型,允许
一个新 ResourceManager 管理跨应用程序的资源使用,ApplicationMaster 负责管理作业
的执行。这一更改消除了一处瓶颈,还改善了将 Hadoop 集群扩展到比以前大得多的配置的
能力。此外,不同于传统的 MapReduce,YARN 允许使用 Message Passing Interface 等
标准通信模式,同时执行各种不同的编程模型,包括图形处理、迭代式处理、机器学习和一般集群计算。
YARN 的工作原理
MapReduce On YARN
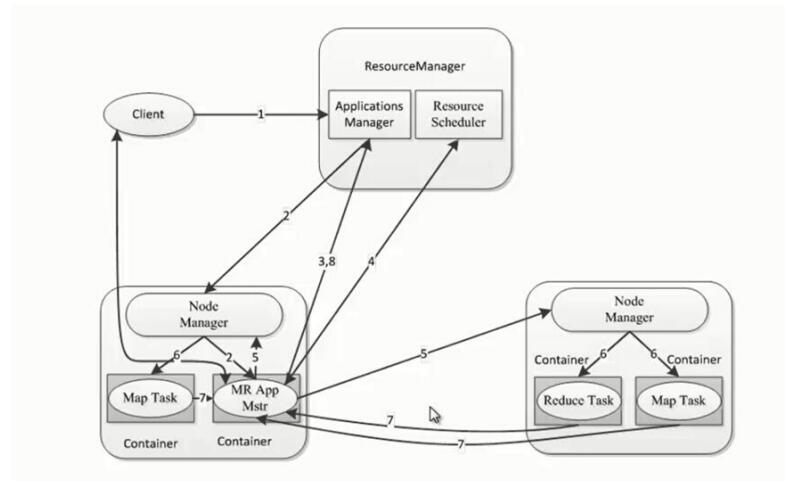
1)YARN 负责资源管理和调度。
2)ApplicationMaster负责任务管理。
MapReduce ApplicationMaster
1)MRAppMaster
2)每个MapReduce作业启动一个MRAppMaster
3)MRAppMaster负责任务切分、任务调度、任务监控和容错等。
MRAppMaster任务调度
1)YARN 将资源分配给MRAppMaster
2)MRAppMaster 进一步将资源分配给内部任务
MRAppMaster容错
1)MRAppMaster运行失败后,由YARN重新启动
2)任务运行失败后,MRAppMaster重新申请资源
YARN HA
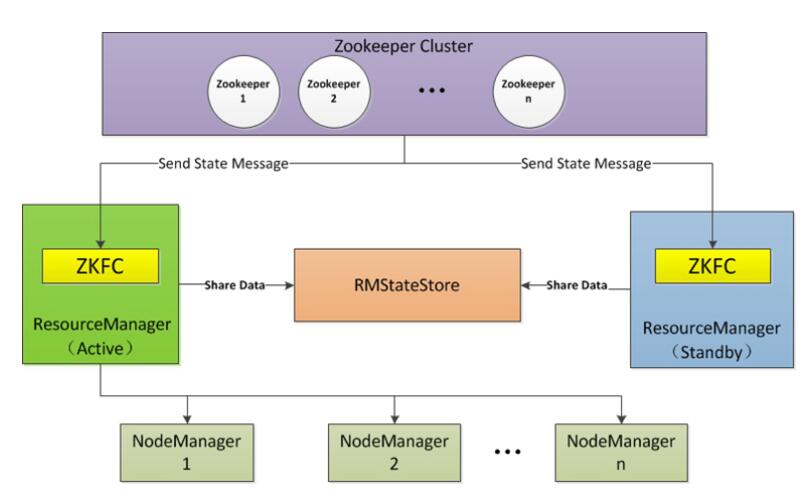
ResourceManager HA 由一对Active,Standby结点构成,通过RMStateStore存储内部数
据和主要应用的数据及标记。目前支持的可替代的RMStateStore实现有:基于内存的
MemoryRMStateStore,基于文件系统的FileSystemRMStateStore,及基于zookeeper的ZKRMStateStore。 ResourceManager HA的架构模式同NameNode HA的架构模式基本一致,数据共享由RMStateStore,而ZKFC成为 ResourceManager进程的一个服务,非独立存在。
总结
1、有关yarn说法正确
A、YARN将资源管理和应用程序管理两部分分剥离开,ResouceManager专管资源管理和调度,而
ApplicationMaster则负责与具体应用程序相关的任务切分、任务调度和容错等
B、YARN具有向后兼容性,用户在MRv1上运行的作业,无需任何修改即可运行在YARN之上。
C、YARN是一个计算框架
D、YARN对于资源的表示以内存为单位,比之前以剩余 slot 数目更合理。
解析:
YARN支持多个框架,它不再是一个单纯的计算框架,而是一个框架管理器,用户可以将各种各样的计算框架移植到YARN之上,由YARN进行统一管理和资源分配,由于将现有框架移植到YARN之上需要一定的工作量,当前YARN仅可运行MapReduce这种离线计算框架。
2、说法正确
A、ApplicationMaster 承担了以前的 TaskTracker 的一些角色,ResourceManager 承担了 JobTracker 的角色。
B、ApplicationMaster 管理一个在 YARN 内运行的应用程序的每个实例。ApplicationMaster 负责协调来自
ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配)。
C、 NodeManager 管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。
D、YARN 继续使用 HDFS 层。它的主要 NameNode 用于元数据服务,而 DataNode 用于分散在一个集群中的复制存储服务。
注意!
本站转载的文章为个人学习借鉴使用,本站对版权不负任何法律责任。如果侵犯了您的隐私权益,请联系我们删除。